Building our new Azure Data Landing Zone IP
 Trent Steenholdt
Trent Steenholdt
December 21, 2023
8 minutes to read
Introduction
After spending around five years in different organisations, I’ve recently rejoined Insight and wanted to share my first exciting story from here. I’ve hit the ground running, focusing on what I do best: building intellectual property (IP), foundational elements, and platforms. Effectively, I see it as the concrete slab to build amazing things on.
In collaboration with Stephen Tulp (aka Tulpy, who has been creating this incredible Bicep Advent calendar you must check out), we’ve developed some outstanding Azure Data Landing Zone IP to assist both current and future customers.
Here is how we did that and what we learnt along the way.
Reviewing existing IP available
So first, we needed to figure out how we could transform our ‘existing’ Azure Data Landing Zone IP as well as those in the open-source community.
Open-source
Starting with the most useful, Microsoft currently has:
Both repositories are MIT licensed, which is great as we can use them as our starting point to help build scalable Azure Data Landing Zones.
Upon review, we determined both are excellent, but they require some in-depth knowledge to set up and work with. Furthermore, they’re quite monolithic in nature, which makes it challenging to extract what you really need. For example, if you’re a small business, you probably don’t need a metadata-driven layer for your Data Factory/Synapse Analytics.
Inner-source
Internally, at Insight, we refer to our repositories as ‘inner-source’, which are essentially internal/closed-source repos. There were about eight repositories that tried to be an Azure Data Landing Zone IP. Like any internal repository in software development, they encountered common pitfalls:
- They were bespoke, designed for a specific need at a specific time, making reusability challenging without significant rework.
- They were built for a time and then became inactive. As people move on, domain knowledge unfortunately often departs with them.
- They followed legacy practices in coding infrastructure as code (IaC), e.g., using CLI calls to ARM templates without a CI/CD pipeline.
Going from Zero to MVP
Solution Architecture
Knowing what we had available to us, we started not quite from scratch, but still had a considerable journey to where we wanted to be. We began, as one should, with our solution architecture, and devised a straightforward design.
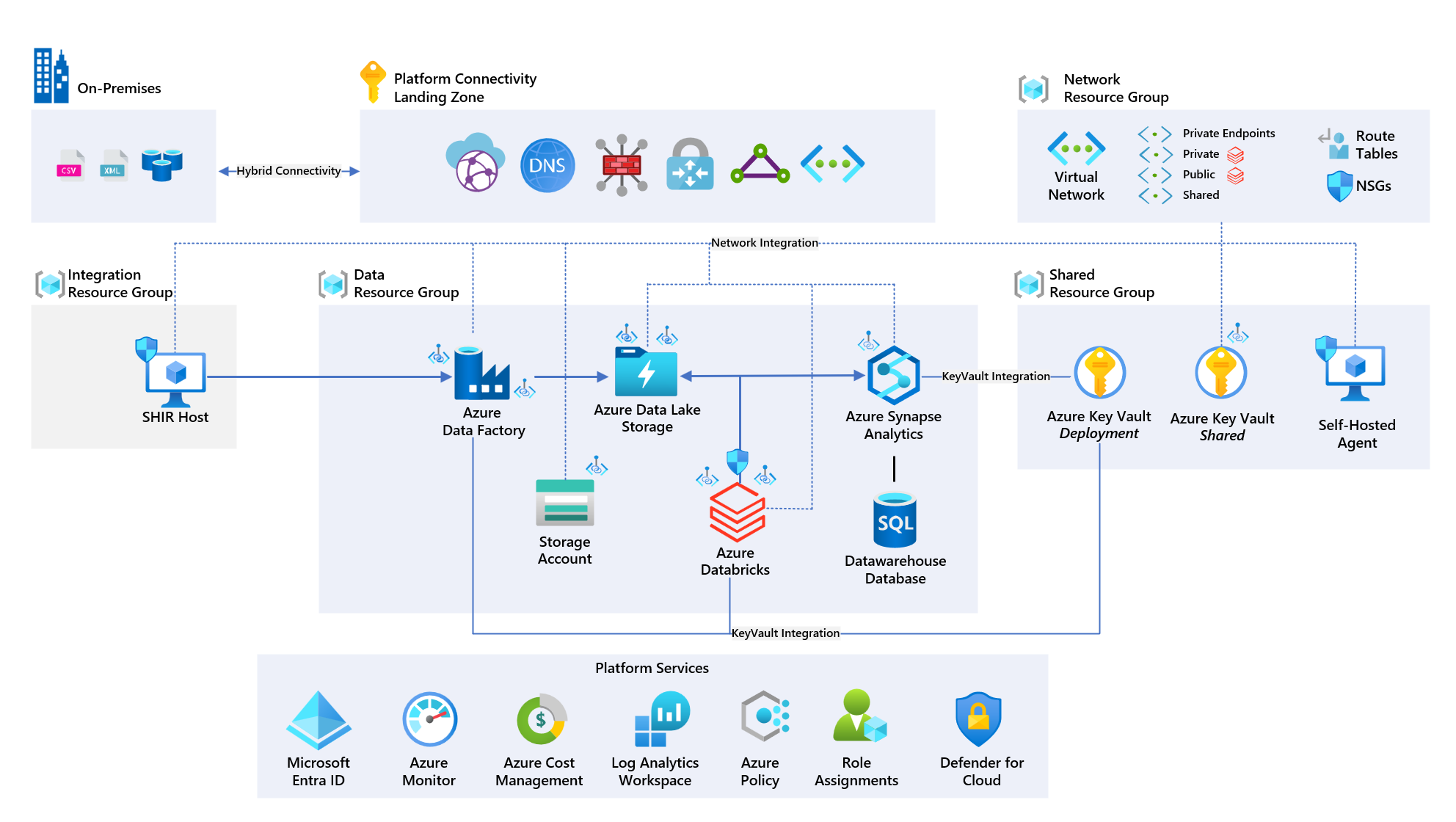
This design meant we were deploying the following resources:
- Key Vault
- Storage Account
- Data Lake Storage Gen2
- Data Factory
- Self-Hosted Integration Runtime
- Synapse Workspace
- Databricks
Additionally, we decided the following services would only be deployed when a boolean condition is met in our configuration files:
The conditions can be toggled wih our wrapper PowerShell scripts. More about that later on.
Repository Structure
With our solution architecture for the MVP in mind, we set about constructing the repository. We opted for a simple folder structure:
- .azdo - Azure DevOps pipelines folder for the solution.
- .github - GitHub Action pipelines folder for the solution.
- .local - Insight’s local development experience, not shared with the customer.
- .vscode - Folder for user and workspace settings in VS Code.
- data - Insight’s supporting artefacts for data ingestion/logic in this solution, e.g., Control_V3, Synapse Workspace configuration, Databricks scripts, and scale files.
- docs - Folder for markdown files in the repository.
- scripts - Folder for generic scripts in the repository.
- src - Bicep IaC modules and parameter files folder for the solution.
- configuration - All associated parameter files, segregated by deployment area.
- modules - All associated Bicep modules, segregated by deployment area.
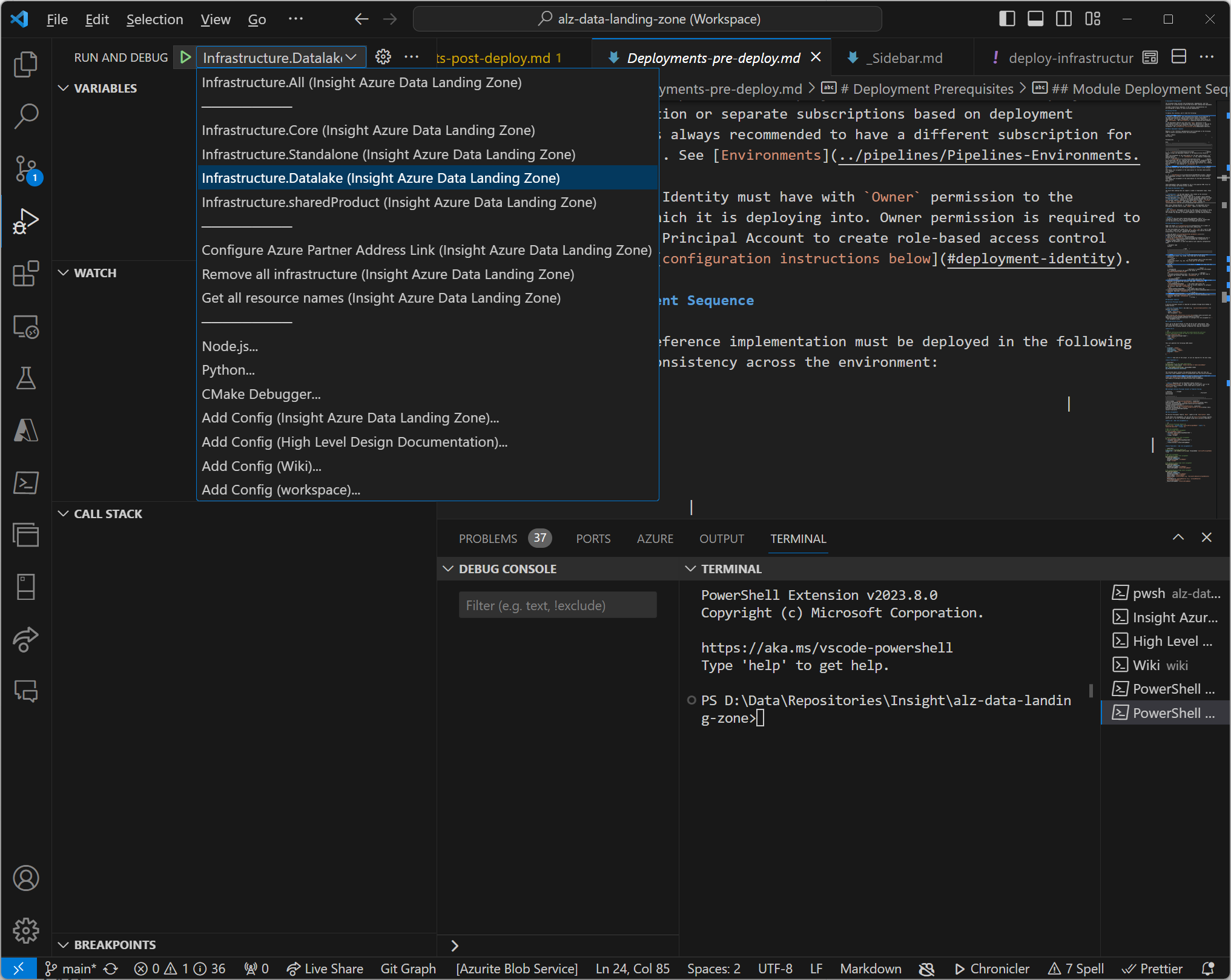
Building the IP
With our repository structure established, we spent the following days amalgamating all the IP.
Bicep
For Bicep, we utilised many of Microsoft’s readily available CARML modules, Bicep templates, and other artefacts. If you’re building your own IP, consider these resources:
We simply called these files in our repository in what we term orchestration Bicep files. These are wrappers for all these modules. For example:
core.biceporchestration file calls modules in/src/modules/CARML*
In summary, we ended up with a few small, repeatable orchestration files. These were:
| Order | Orchestration | Description | Prerequisites | Note |
|---|---|---|---|---|
| 1 | core | Deploys Resource Groups and Deployment KeyVault in the Administration Resource Group. | Owner role assignment at the subscription for the Data subscriptions (e.g. Vending Machine) | - If isStandalone is true, deploys a Networking Resource Group also. |
| 2 | standalone | Deploys Azure Networking, DNS etc., implying that this solution is standalone and not part of an Azure Landing Zone Vending Machine deployment. | Owner role assignment at the subscription for the Data subscriptions (e.g. Vending Machine) | - Only deploys if isStandalone is true |
| 3 | datalake | Deploys Azure Data Factory and the Self-Hosted Integration Runtime virtual machine(s). | Contributor role assignment at the subscription for the Data subscriptions (e.g. Vending Machine) | |
| 3 | sharedProduct | Deploys Azure Databricks workspace (vNet Injection method only) and Azure Synapse workspace. | Contributor role assignment at the subscription for the Data subscriptions (e.g. Vending Machine) |
Pipelines, Pipelines, and More Pipelines
As evident from the orchestration files table above, the orchestration must be executed in a specific order, facilitated by PowerShell and either GitHub Action or Azure DevOps pipelines (we support both).
The strength of our approach lies in our neat PowerShell wrapper scripts. While Bicep is effective, it’s limited in enabling full end-to-end deployments as it’s not a high-level programming language, a fact acknowledged by Microsoft in their Bicep repository.
Therefore, we wrapped all our orchestration Bicep file deployments in PowerShell, allowing outputs from one Bicep file to be passed to the next. This also allowed us to facilitate different needs like standalone set ups or those that integrate with some our other IP.
This approach provides rapid scalability while maintaining simplicity in terms of repeatability. It’s so straightforward that, aside from the subtle differences in GitHub Actions and Azure DevOps Pipelines, we can run the same code throughout. Additionally, this code is also utilised in our local IDE experience; again making real easy to build out the IP without having to wait for a pipeline to run!
Deployment
Finally, we have the actual deployment in action. As mentioned earlier, we’re using the same PowerShell wrapper script for our end-to-end solution deployment.
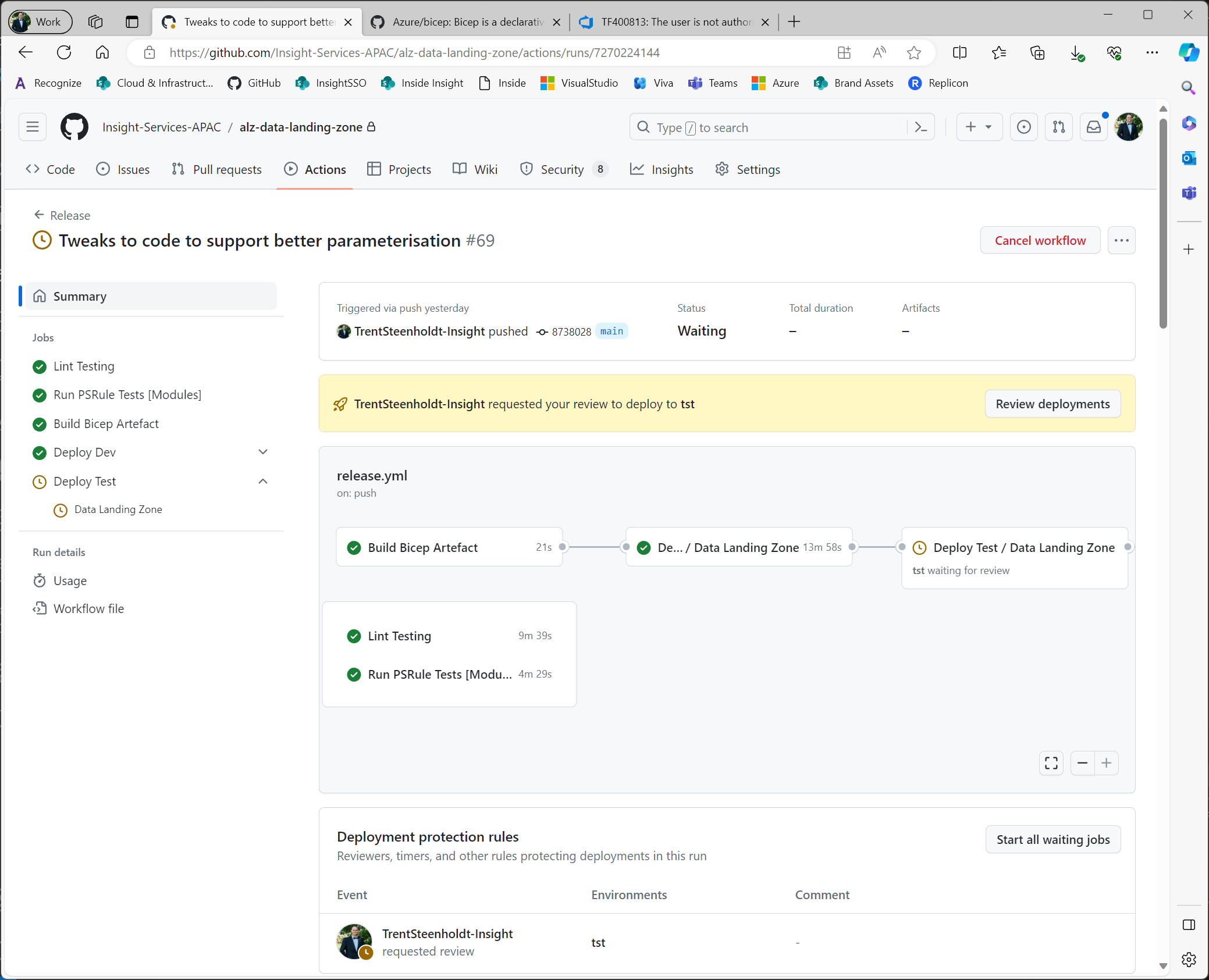
We do all the normal and expected steps here by making our code repeatable, nested in actions (GitHub specific) and set up approval gate for each environment.
Key Learnings and Takeaways
This journey has been an enriching experience, filled with learnings and insights. Here are some key takeaways:
- The Power of Collaboration: Working closely with a skilled and motivated team can exponentially increase productivity and creativity.
- Leveraging Existing Resources: Efficiently utilising available resources and building upon them can save time and foster innovation.
- Rapid Prototyping and Flexibility: In a time-constrained project, the ability to quickly prototype, test, and adapt is invaluable.
- Effective Repository Practices: We started building our IP by enforcing branching policies and making both of us work off a branch. While that may seem tedious early days, it allowed myself and Tulpy to rapidly build without causing each other too much pain.
- Focus on the End Goal: Keeping the end-user (our internal professional services teammates) in mind throughout the development process ensures that the final product is not only technically sound but also user-friendly and practical.
Connect with us to learn more
If you’re interested in what we’ve built and want to learn more about our journey and explore our Azure Data Landing Zone IP, feel free to connect with us via our personal socials or by contacting Insight directly.