Embedding and Vector Search Using Azure OpenAI
Author:
Daniel Fang
Published: May 27, 2024
12 minutes to read
With the increasing complexity of data and the rise of artificial intelligence, there is a growing need to search, classify, and retrieve information more efficiently. Traditional keyword-based search techniques are becoming less effective as datasets expand in volume and complexity. This is where embedding and vector search come into play. Combined with Azure OpenAI’s advanced AI capabilities, these techniques offer a robust solution for semantic search, similarity detection, and recommendation systems.
In this blog post, we’ll explore how to use embeddings and vector search, together with Azure OpenAI, to improve traditional search. Azure OpenAI offers powerful, pre-trained embedding models for generating embeddings that capture deep semantic relationships in text and other data.
What is Embedding?
Embedding is the process of converting high-dimensional data (like text or images) into a fixed-size vector of numbers, which is often of much lower dimensionality. These vectors capture the semantic meaning of the input data, allowing similar data points to be represented by vectors that are close to each other in the vector space.
For instance, in a text-based search engine, traditional search might look for the occurrence of exact keywords. However, embedding allows the system to understand that terms like “dog” and “puppy” are semantically related, even if they don’t share the exact same words. This makes search and recommendation systems far more intelligent and context aware.
What is Vector Search?
Vector search, also known as similarity search or semantic search, involves finding vectors in a high-dimensional space that are most similar to a given query vector. When used in conjunction with embeddings, vector search allows you to retrieve the most semantically relevant items based on their vector proximity, rather than simple keyword matching.
For example, a vector search for “smartphone” could return results including “mobile phone” and “cell phone,” based on their similarity in the vector space. This contrasts with traditional search methods, which might miss these connections if the exact term isn’t used.
How Does Embedding and Vector Search Work?
Let’s walk through an example of setting up a document search system using Azure OpenAI. Users can search for documents based on semantic relevance, rather than just keyword matching.
- Generate Embeddings: You input text or other data into an OpenAI model, which returns a vector embedding representing the semantic content of the data.
- Perform Vector Search: Once you have the embeddings, you can perform a vector search by comparing the distance between the query embedding and the stored embeddings. Typically, the distance is measured using cosine similarity or Euclidean distance.
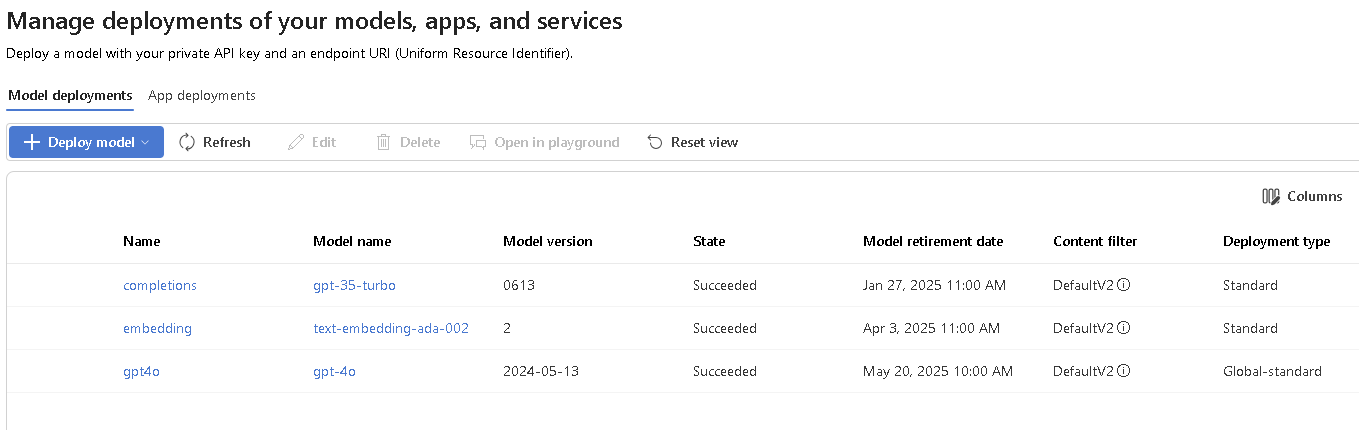
Step 1: Deploy Embeddings Model
Firstly, you’ll need access to the Azure OpenAI service. If you don’t already have an account, you can sign up through the Azure portal.
Once the Azure OpenAI service is set up, you can access the Restful API for generating embeddings. In our case, we’ll use the text-embedding-ada-002 model, which is optimized for text-based embeddings.
Step 2: Generate Embeddings
The next step is to convert each document into an embedding using Azure OpenAI. Suppose you have a dataset of documents, and you want to allow users to search through these documents based on their meaning.
Here’s how you can generate embeddings for a batch of documents using the Azure OpenAI API. Save below python script in a file called gen.py.
import openai
import os
import json
# Set up the API key and endpoint
openai.api_type = "azure"
openai.api_key = "<YOUR_API_KEY>"
openai.api_base = "https://<YOUR_ENDPOINT_URL>.openai.azure.com"
openai.api_version = "2023-03-15-preview" # Replace with your API version if different
# Sample documents to generate embeddings for
documents = [
"Artificial intelligence is transforming industries.",
"Machine learning enables computers to learn from data.",
"Natural language processing powers voice assistants."
]
response = openai.Embedding.create(
input=documents,
deployment_id="embedding" #text-embedding-ada-002
)
# Create a list to hold text and embedding pairs
embeddings_data = []
for doc, data in zip(documents, response['data']):
embedding = data['embedding']
embeddings_data.append({
'text': doc,
'embedding': embedding
})
# Print text and first 10 elements of each embedding
for item in embeddings_data:
print(f"Text: {item['text']}")
print(f"Embedding (first 10 elements): {item['embedding'][:10]}")
print() # Add an empty line for better readability
# Save embeddings to a JSON file
with open('embeddings.json', 'w') as f:
json.dump(embeddings_data, f)
print("Embeddings have been saved to 'embeddings.json'")
Run above python script.
python gen.py
It will output embedding for each sample text like blow. The large array of decimal numbers is the embedding.
PS D:\blog> python gen.py
Text: Artificial intelligence is transforming industries.
Embedding (first 10 elements): [-0.01281912624835968, -0.022458212450146675, 0.0047238776460289955, -0.0041729784570634365, 0.00444018142297864, 0.0028567584231495857, -0.025651447474956512, 0.010641920380294323, 0.001298076706007123, -0.036418721079826355]
Text: Machine learning enables computers to learn from data.
Embedding (first 10 elements): [-0.03261930122971535, -0.004467426333576441, 0.011984048411250114, -0.022743260487914085, -0.00045770168071612716, 0.029473409056663513, -0.0001311460364377126, -0.005995247513055801, -0.012306373566389084, -0.030298560857772827]
Text: Natural language processing powers voice assistants.
Embedding (first 10 elements): [-0.00976149644702673, -0.000182717849384062, 0.005995875224471092, 0.005393640603870153, -0.0012110874522477388, 0.014691879972815514, -0.00995341781526804, -0.02202458493411541, -0.00312864244915545, -0.034016333520412445]
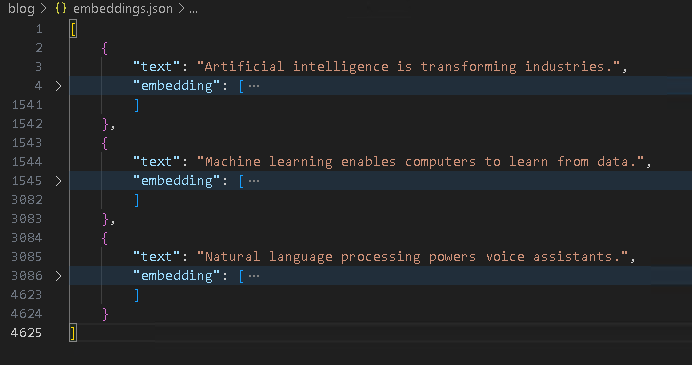
Step 3: Store Embeddings
Now that we have the embeddings for each document, these can be stored in a database or a vector search engine like Azure Cognitive Search and MongoDb.
To keep this exercise simpler, we will simply store the original text and its embedding in a json file instead.
Step 4: Vector Search
The final step is to perform vector search. When a user submits a query, we need to convert that query into an embedding using the same model. Then, we compare the compare this embedding with other stored embeddings to find the most similar documents.
Here’s how you can run vector search based on a user’s query:
import numpy as np
import openai
import json
import os
# Set up the API key and endpoint
openai.api_type = "azure"
openai.api_key = "<YOUR_API_KEY>"
openai.api_base = "https://<YOUR_ENDPOINT_URL>.openai.azure.com"
openai.api_version = "2023-03-15-preview" # Replace with your API version if different
# User query
query = "How does AI change industries?"
# Generate embedding for the query using the deployment ID
query_embedding_response = openai.Embedding.create(
input=[query],
deployment_id="embedding" #text-embedding-ada-002
)
# Extract the embedding vector
query_embedding = query_embedding_response['data'][0]['embedding']
# Load embeddings from 'embedding.json'
with open('embeddings.json', 'r') as f:
embeddings_data = json.load(f)
# Extract texts and embeddings from the loaded data
texts = [item['text'] for item in embeddings_data]
embeddings = [item['embedding'] for item in embeddings_data]
# Convert embeddings to NumPy arrays
embeddings = np.array(embeddings)
query_embedding = np.array(query_embedding)
# Define custom cosine similarity function
def cosine_similarity(a, b):
"""Calculate the cosine similarity between two vectors."""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Compute cosine similarity between query embedding and each document embedding
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
# Convert similarities to a NumPy array
similarities = np.array(similarities)
# Rank documents based on similarity
top_doc_index = np.argmax(similarities)
print(f"Most similar document: {texts[top_doc_index]}")
# Optional: Print all documents with their similarity scores
print("\nAll documents and their similarity scores:")
for text, similarity in zip(texts, similarities):
print(f"Text: {text}")
print(f"Similarity Score: {similarity:.4f}\n")
The system retrieves the most semantically relevant documents, even if the query doesn’t contain exact keywords from the documents. Similarity Score indicates the match score for each stored document.
PS D:\blog> python calc.py
Most similar document: Artificial intelligence is transforming industries.
All documents and their similarity scores:
Text: Artificial intelligence is transforming industries.
Similarity Score: 0.9281
Text: Machine learning enables computers to learn from data.
Similarity Score: 0.8118
Text: Natural language processing powers voice assistants.
Similarity Score: 0.7824
Conclusion
Embedding and vector search are revolutionizing how we interact with and retrieve information from large datasets. By leveraging the power of Azure OpenAI, you can build sophisticated, AI-driven search and recommendation systems that go beyond traditional keyword-based approaches.
With embedding, your systems can understand the context and meaning of data, while vector search ensures that the most semantically relevant results are surfaced to users. Whether you’re building a search engine, recommendation system, or knowledge discovery platform, combining these technologies with Azure OpenAI opens up a world of possibilities.